Method Overview
Core Idea
Estimate the importance of spatial relations and choose a set of relations with O(n) size that contains all key spatial relations that are used for spatial reasoning.
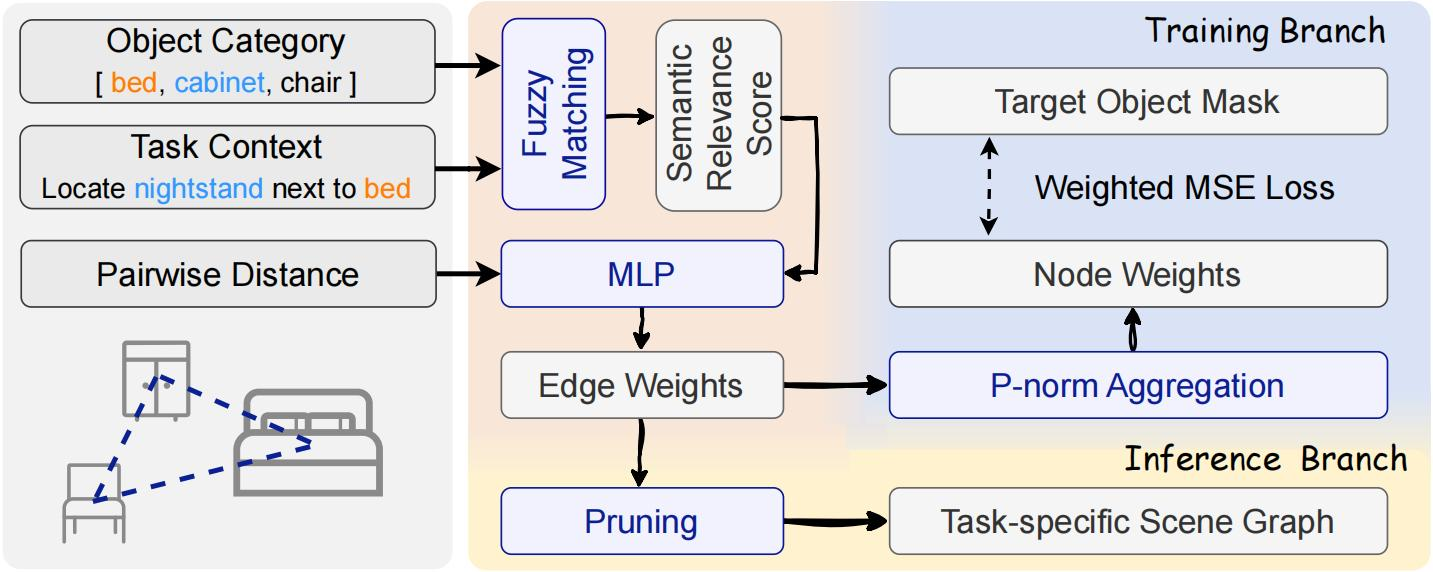
Figure 1: The model architecture of CAPruner.
CAPruner
- Estimates object-query semantic relevance via fuzzy matching on object categories.
- Combines semantic cues with geometric spatial proximity to predict edge weights.
- Adaptively prioritizes query-relevant spatial relations.
- Achieves high token efficiency (34% reduction in token usage).
Node-wise Supervision
- Employs p-norm aggregation to aggregate edge weights into node weights.
- Supervises node weights using only available target object labels, avoiding costly relation-level annotations.
- Utilizes a Weighted MSE loss to balance the contributions of target and non-target objects.